 相信大家都已经顺利配置好Openclaw,并成功拉通聊天对话
相信大家都已经顺利配置好Openclaw,并成功拉通聊天对话
但你是不是感觉,并没有网上吹的那么牛逼?
不稳定
不够聪明
还特别烧钱
“单点工具”的玩法,注定无法发挥龙虾的全部实力。
我新开这个【神器篇】系列,旨在帮助大家,更快,更省成本的拉高 OpenClaw 的能力上限! 从【模型、设备、Skills、浏览器交互、GitHub武器库、n8n自动化工作流】的角度, 用“强强联动”的思路,把 OpenClaw 的能力上限真正拉满。
怎么样?朋友们,你们的小龙虾好玩吗?
- 够不够聪明?
- 是不是经常性失忆?
- Token还在燃烧吗?
- 输出的结果还理想吗?
- 废了大功夫配置云端服务器,结果能做什么?
这篇笔记,就从模型、设备的角度,帮你解决卡住你畅快玩小龙虾的第一道坎!
- 自动化最强模型组合:整合最强的模型,能力拉满
- 多家模型薅羊毛攻略:省到就是赚到
- 设备选择避坑:选对设备少折腾
选对模型省力一半,选对设备法力无边
模型是OpenClaw的大脑,设备是OpenClaw的手脚;两者选好,才能拉爆小龙虾的能力上限!

怎么选模型?强大、便宜、无限额!
想的有点太美了吧! 模型的不可能三角就是:聪明、便宜、无限额。
虽然要认清这个事实,但并不意味着完全没有折中地带,今天这篇笔记就帮你做到一个三者兼得的搭配方案!
开始之前我们先来看看模型的能力排行!
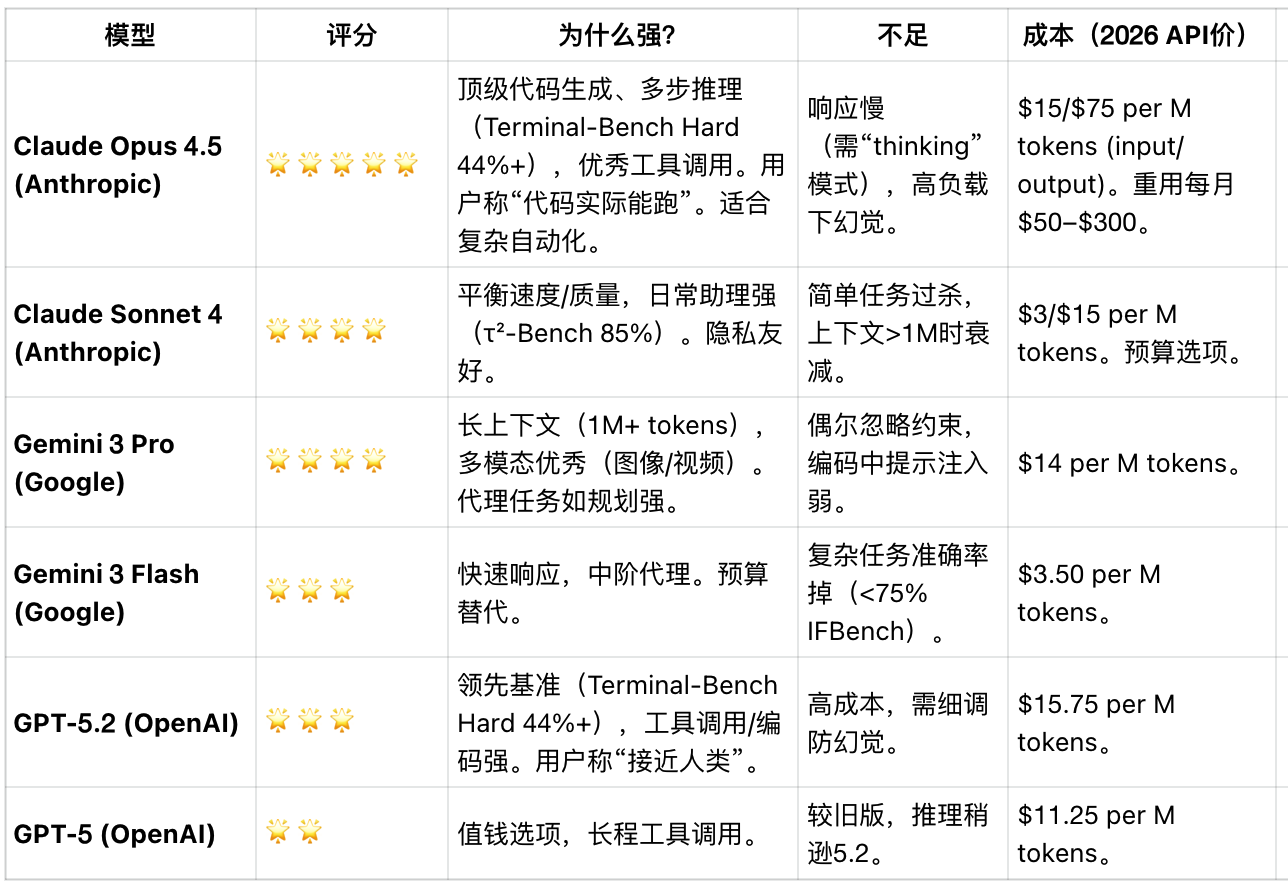
模型综合排行榜(能力/成本/优势/劣势)
每个模型都有不同定位及优势,编码、全模态、生图、速度等等。
闭源模型评分榜
开源模型评分榜
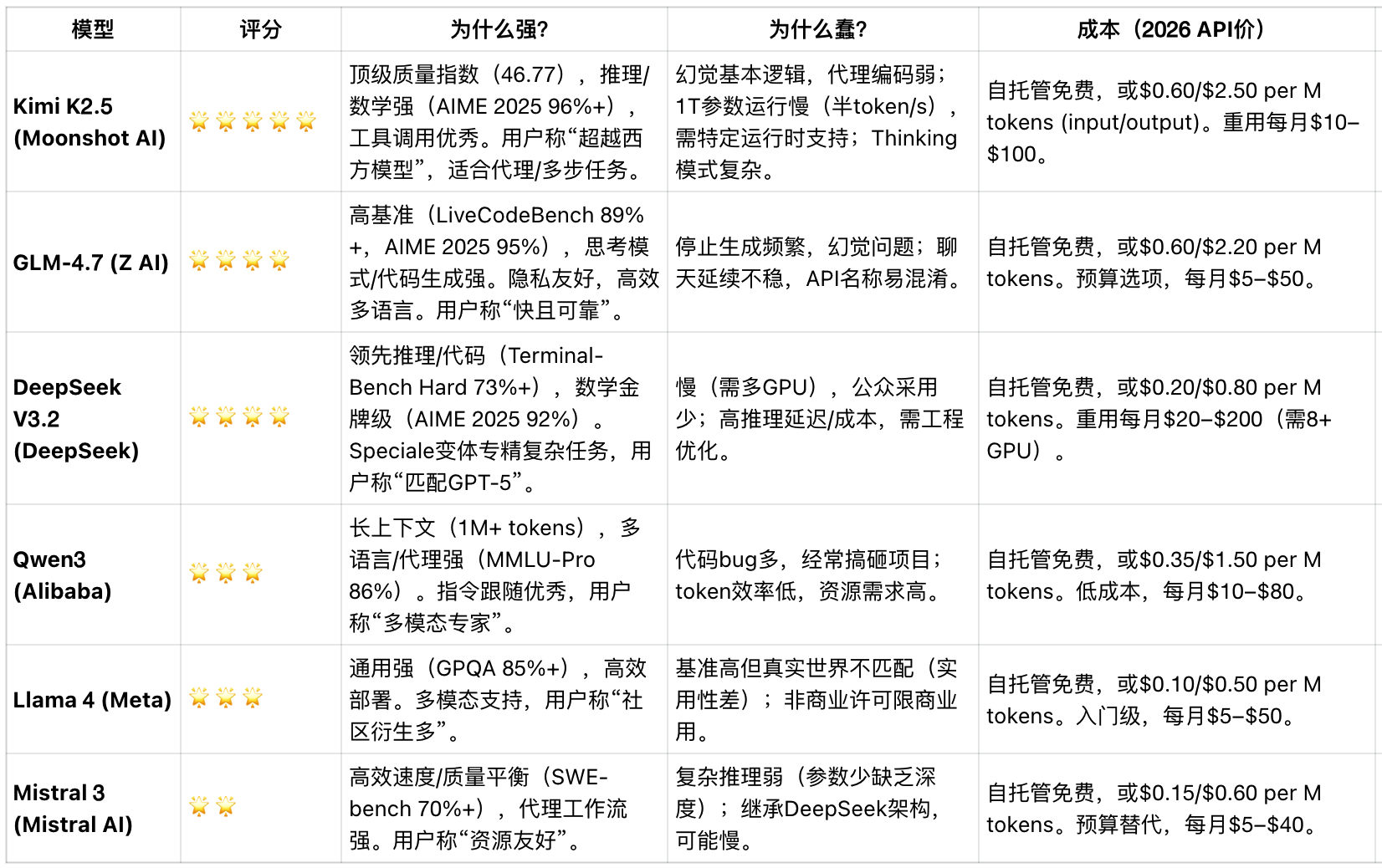
没有绝对最好的模型,只有最满足你需求的模型
选择模型没有必要追求所谓的最好,一定要根据你的应用场景来选择。
模型推荐
【Claude】 如果你是程序猿、重度使用者,一定会首选 Claude 的模型,公认的写代码最强,推理逻辑能力最强。 【Gemini】 如果你是普通玩家,Gemini是综合能力是最强的,长上下文、多模态能力,能满足你更多生活场景。 【其他】 OpenAI、Qwen、Deepseek都有各自的优势,大家根据需要选择。
那既然没有最强,我的需求场景又比较多元,又不想多花钱!!!怎么办?
从上图可以看到,这些强的模型价格都不菲,一个订阅大概20美刀/每月,不过好在所有的模型厂商都有免费的额度,我们就利用这个额度福利,来搭建最强模型组!
不想多花钱,2步打造最强的模型组!!!
既然模型也没有绝对的最强者,各自都有各自的优势,那搭配组合使用一定会是1+1大于2的提升,同时还能更节省成本!
恰好OpenClaw又天然带 Session Spawn (子Agent) 机制,恰好可以帮助我们打造一个属于你最强的模型组!
定制模型组规则有什么优点?
- 能发挥各个模型的最强优势,多模型组合1+1>2!
- 能薅各家模型羊毛,在限额内能省一大笔钱!
- 能结合OpenClaw配置规则,根据任务自动化切换,省时省力!
我在OpenClaw上构建了一个自动化切换系统,指定不同的模型执行不同的任务,仅需2步!
第一步:”主脑 + 干活分身“ 模型组结构
通过OpenClaw的 Session Spawn (子Agent) 机制实现
- 主脑:Gemini,足够聪明,负责理解你的意图,成本可控
- 分身1:写代码,召唤子Agent 1,指定它使用Claude / Qwen coder
- 分身2:数据分析,召唤子Agent 2,指定使用 GPT- OSS 20 B(本地模型)
基本上大量数据分析的事情拆分出来,你的API Token消耗不会特别的多,薅羊毛的限额以内也够用!
按照这个逻辑,让OpenClaw构建自动切换机制
!!!【一定要做下面设置】 “在核心记忆中记录下以下规则,当我与你对话时,调用主机制模型;当我提到一些关键字任务时,自动切换对应的模型执行“
(👇可以参考我的写法)

小技巧:在你的核心记忆中写入规则,模型回复带上当前模型的提供商及模型名/或者用你自己喜欢的方式识别,方便你知道是那个模型做的执行!

第二步:把配置写进OpenClaw(规则机制)
这是核心。所有的“自动切换逻辑”都要写进配置文件里,这是OpenClaw执行规则的基础。

配置好后如何调用操作?
你可以直接自然对话或者通过 /model 指令强制指定当前会话或下一条回复的模型。
• @Clawdbot /model deepseek-coder-v2 (切换当前会话模型)
• @Clawdbot /spawn model=deepseek-coder-v2 task=“写个脚本…” (强制指定子 Agent 执行任务)
配置好这个自动切换机制,你的龙虾就能自动分配执行任务。
为什么我让龙虾记住,它还是经常失忆?
这个是近期大家反馈最多的问题。
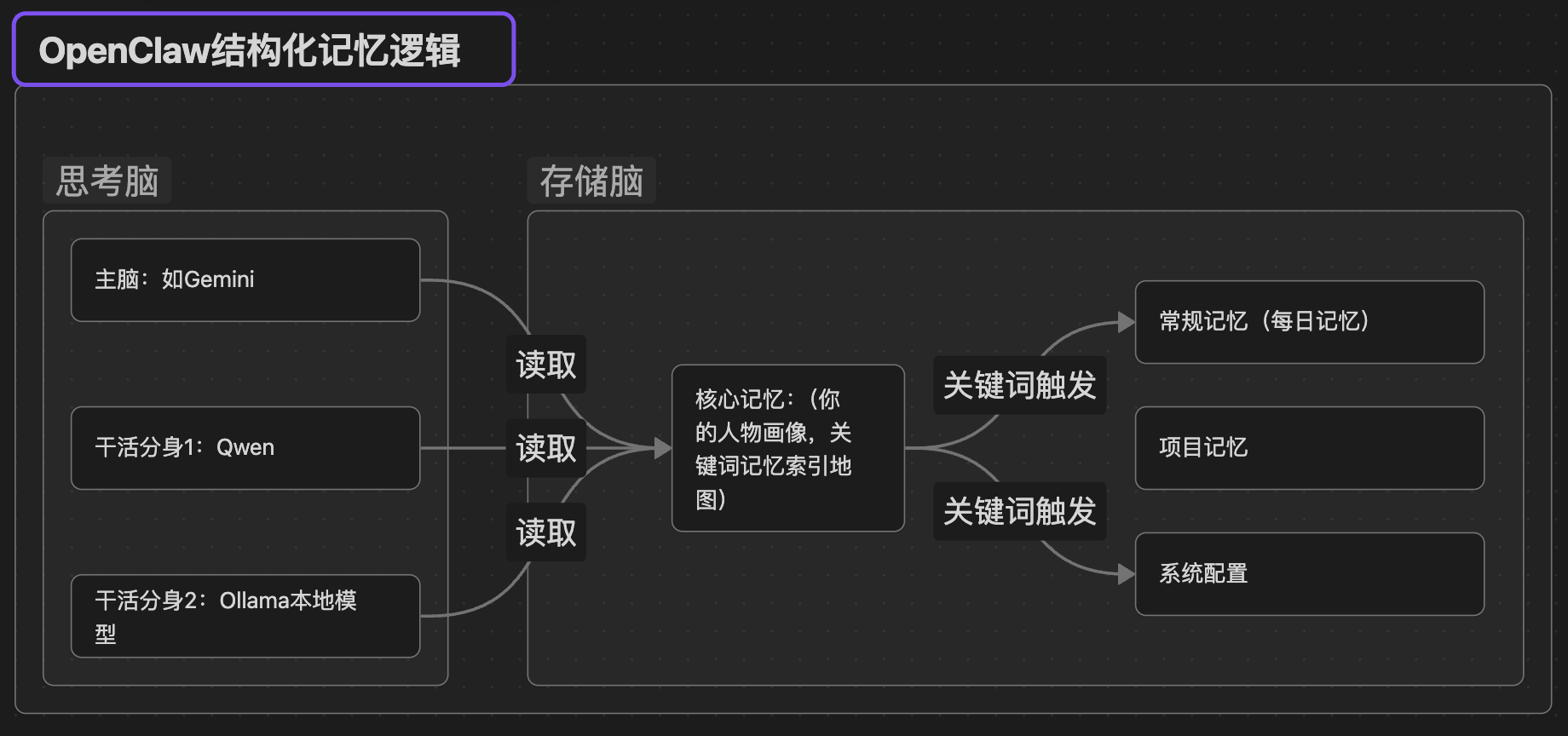
我们先来理解一下 OpenClaw 运行机制,它其实有两个脑
- 思考脑:你接入的大模型,负责读取分析思考输出,但不负责记忆(仅有临时上下文记忆)
- 存储脑:存储在本地的memory,负责记录对话,关于你的一切,系统配置等。
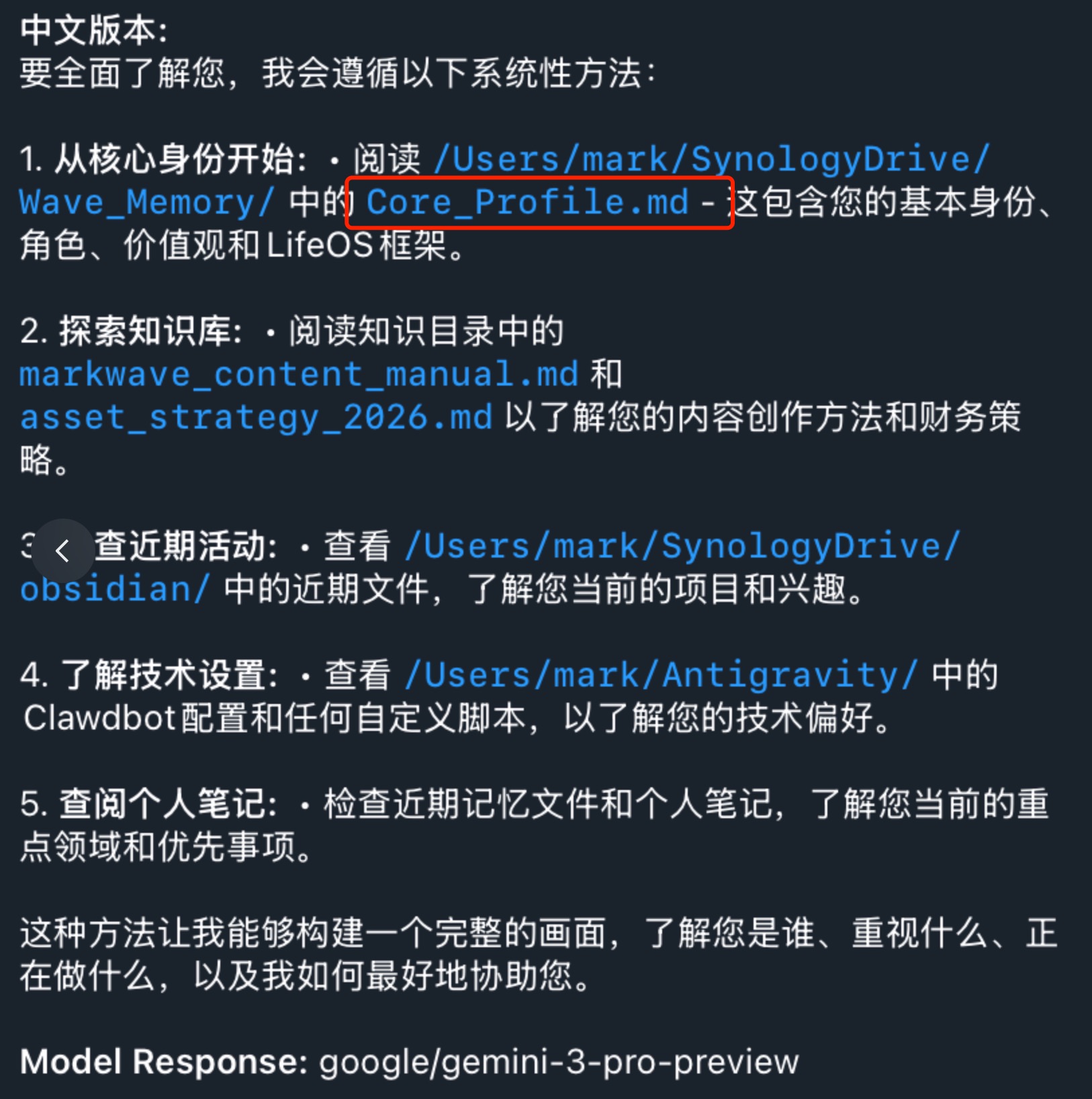
 你可以问你的模型,如果你要了解我,你会怎么做?你会读取什么文件?
你可以问你的模型,如果你要了解我,你会怎么做?你会读取什么文件?
大模型读取了解你的逻辑是什么样的?
- 读取核心memory:这里是新模型读取的第一个文件。
- 渐进式读取:当一些关键词触发时,他会深入读取你的相关记忆/skill/笔记等内容。
按照这个逻辑不难看出,核心记忆是模型了解你的第一入口,这里有什么,模型就能读到什么! 至于你每天跟OpenClaw对话的零散记忆及关键点,如果核心记忆里没有,模型就无法/很难读到。
那是不是意味着,我要把所有记忆都堆到核心记忆里,喂给模型? 又回到之前的问题,你的模型反应速度会极慢甚至卡死;你的Token分分钟就爆掉!
用渐进索引的方式,2步构建你的【结构化记忆】
- 在你的核心记忆中,建立关键词索引,包含你对话的关键词,构建项目的目录等
- 设定自动记录规则,要求龙虾每天汇总对话记忆关键词,更新到核心记忆中
这个能够有效的解决模型失忆的客观问题(如果大模型本身的问题,那没办法等迭代更新)。
不过,随之而来另外一个小问题,日积月累,虽然模型看到你的人物画像越来越清晰,但是核心记忆的体积也在变大,对Token也会造成压力。建议你定期手动删除一些重复/废弃的项目。
说了这么多,我就是想用不花钱的模型,怎么办?
模型薅羊毛攻略
看看我一个周Gemini API的消耗(在我优化了结构后,Token消耗降低的非常明显,但9天时间依然消耗了176美刀!)
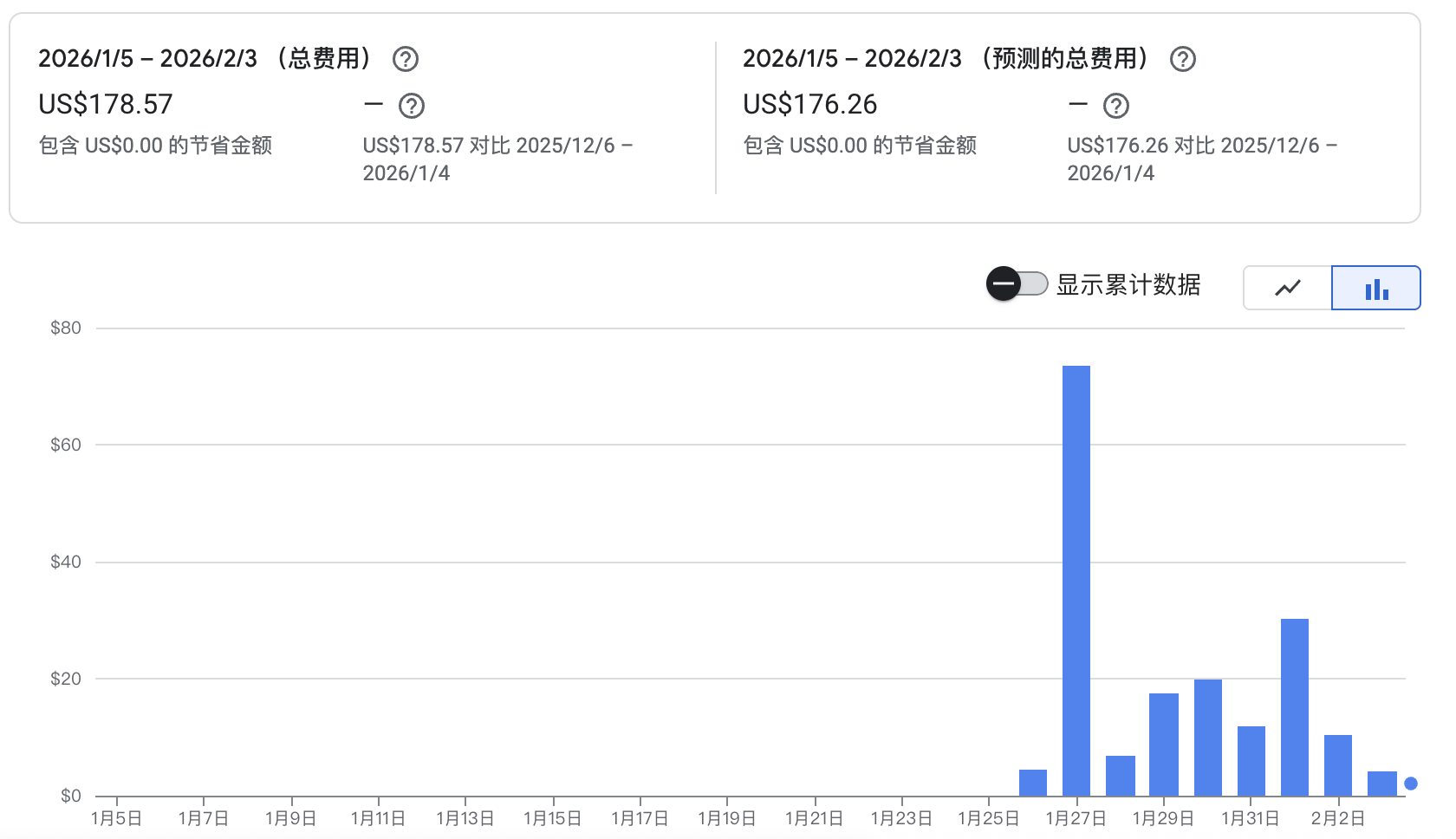
那么,在没有达成生产力输出前,投入这么多成本,这么低的ROI,没几个人能接受吧! 如果你是财大气粗的订阅用户,请直接忽略~
我整理了薅羊毛实录,收录了多家平台的免费模型/API攻略持续更新(放在知识库)
Google 薅羊毛实录
【强烈推荐】
Google AI Studio 提供免费的API,虽然有速率限制,但按照【结构化记忆】对话,也挺够用
- 足够聪明
- 多模态能力强
- 能生图,调用nano banana(有限制)
【可选推荐】
Google cloud,新用户有300美刀的赠金,但是消耗非常快,一两周就差不多没了。如果你需求很少的可以用,但是要注意赠金用完会产生真实费用,并且如果扣款失败/拖着不交,会直接关闭Google cloud账户。
【其他选择】
路由器混合API,费用节省30% OpenRouter Opencode
【免费】
Qwen、DeepSeek、本地部署开源模型
选好设备法力无边!
OpenClaw 部署虽说简单不吃设备,但是你给他什么样的设备,它给你干什么样的活儿。
云端部署 = 能力上限低
本地设备 = 真正的中枢
如果你要部署云端,我劝你直接Gemini/ChatGPT/豆包对话框,因为部署了你会发现,它甚至还不如豆包体验好!
越强的设备,你能联动的神器就越多,OpenClaw的能力上限就越高。 推荐大家根据需求尽可能选择高配置的。
不要为了省几百块, 折腾 VPS / NAS / 云端部署几周。 但你算一笔账:
时间成本
能力上限
调试风险
还不如直接国补一台 Mac mini。
低功耗,稳定长期运行,安静无噪音。
OpenClaw强强联动神器系列
1️⃣ 模型 & 设备:决定上下限 2️⃣ Skills:学会干细活儿 3️⃣ 浏览器 & CLI:真正接触世界 4️⃣ n8n:让一切自动跑起来
预告:
下一篇,将展开讲讲被百万大V推崇的 Skills,到底能给你带来多少的效率提升?
欢迎关注更新~